Abstract
The rapid integration of large language models (LLMs) into high-stakes legal work has exposed a critical gap: no benchmark exists to systematically stress-test their reliability against the nuanced, adversarial, and often subtle flaws present in real-world contracts. To address this, we introduce CLAUSE, a first-of-its-kind benchmark designed to evaluate the fragility of an LLM's legal reasoning. We study the capabilities of LLMs to detect and reason about fine-grained discrepancies by producing over 7,500 real-world perturbed contracts from foundational datasets like CUAD and ContractNLI. Our novel, persona-driven pipeline generates 10 distinct anomaly categories, which are then validated against official statutes using a Retrieval-Augmented Generation (RAG) system to ensure legal fidelity. We use CLAUSE to evaluate leading LLMs' ability to detect embedded legal flaws and explain their significance. Our analysis shows a key weakness: these models often miss subtle errors and struggle even more to justify them legally.
Overview
CLAUSE advances legal reasoning evaluation through systematic analysis of contractual discrepancies. Built upon two established legal corpora (CUAD and ContractNLI), our framework represents the first fully AI-generated legal contradiction dataset.
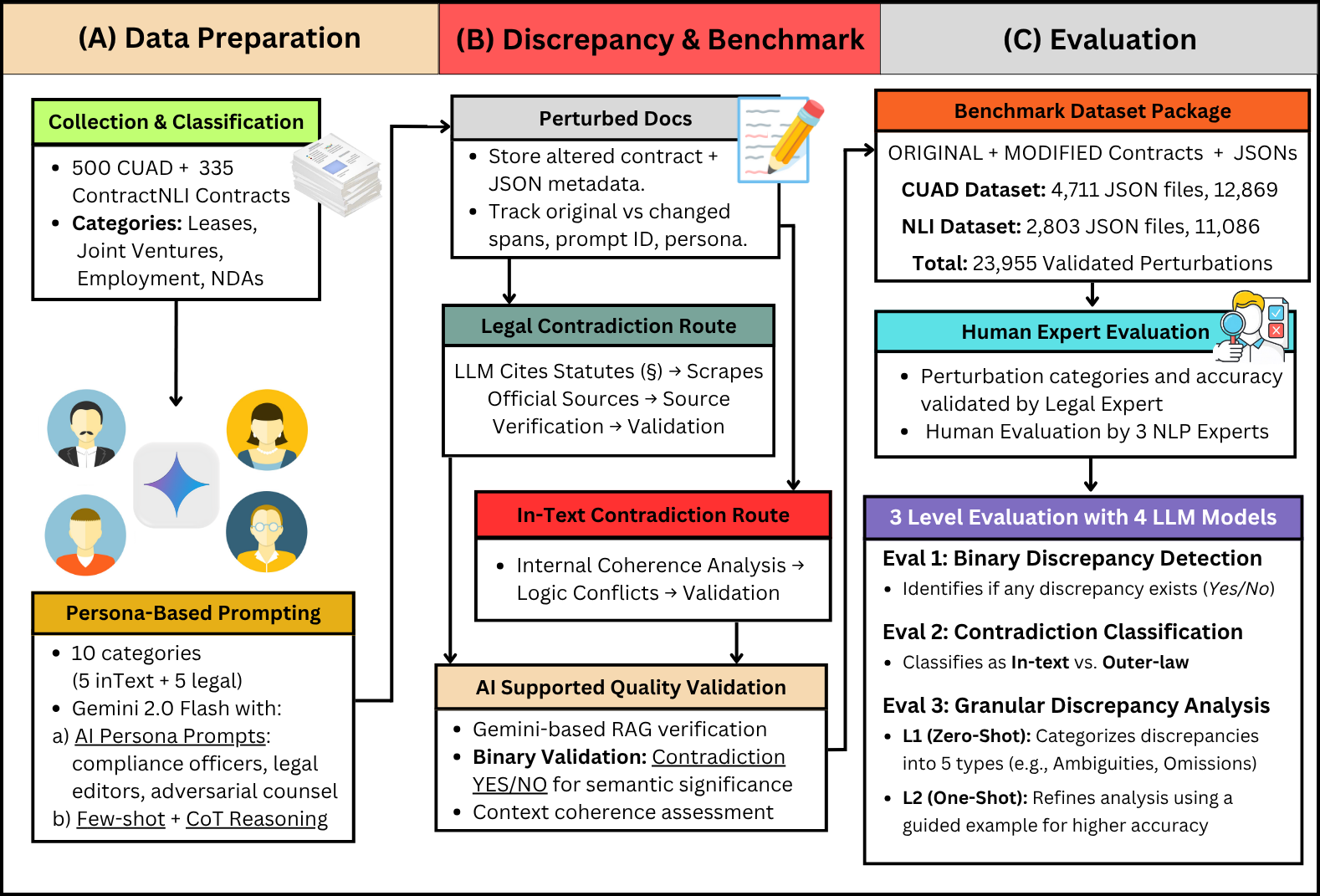
Figure 1: CLAUSE pipeline showing Data Preparation, Discrepancy & Benchmark generation, and Evaluation phases.
Video Presentation
A 10-minute overview of the CLAUSE benchmark and key findings.
Key Contributions
First benchmark for fine-grained legal contradictions with ten perturbation types grounded in statutory requirements.
Automated AI pipeline generating and validating contradictions with RAG-based statutory grounding before expert review.
Rich metadata framework capturing context, reasoning chains, and contradiction strength for reproducibility.
Extensive evaluation uncovering systematic legal reasoning weaknesses across varied prompting strategies.
Dataset
CLAUSE implements a comprehensive taxonomy of modifications featuring two fundamental dimensions:
Legal Contradictions
Modifications that conflict with statutory requirements, regulatory standards, or legal precedents, creating compliance issues that could render clauses unenforceable.
In-Text Contradictions
Modifications creating logical inconsistencies within the document itself, where different sections provide conflicting information or obligations.
Perturbation Categories
Ambiguity
Introduction of vague, unclear, or contradictory language creating uncertainty in interpretation, making contract terms susceptible to multiple conflicting meanings.
Omission
Deliberate removal or absence of critical information, clauses, or terms necessary for complete understanding or legal enforceability.
Misaligned Terminology
Inconsistent use of defined terms throughout the document, or terminology conflicting with established legal definitions.
Structural Flaws
Modifications disrupting logical organization, hierarchy, or cross-referencing within the contract.
Inconsistencies
Direct contradictions between different sections where statements, obligations, or terms are mutually exclusive.
Dataset Statistics
| Category | InText | Legal | ||
|---|---|---|---|---|
| Files | Pert. | Files | Pert. | |
| Ambiguity | 741 | 2,417 | 805 | 2,472 |
| Inconsistency | 749 | 2,357 | 830 | 2,711 |
| Misaligned Terminology | 772 | 2,636 | 834 | 2,864 |
| Omission | 754 | 2,498 | 698 | 2,111 |
| Structural Flaws | 760 | 2,540 | 571 | 1,349 |
| Totals | 3,776 | 12,448 | 3,738 | 11,507 |
Evaluation Tasks
We define three hierarchical tasks to assess LLM capabilities in detecting and reasoning about legal discrepancies:
Binary Discrepancy Detection
Given a document, predict whether any discrepancy is present (Yes/No classification).
Contradiction Type Classification
Classify contradictions as: (1) in-text contradiction, (2) legal/outer-law contradiction, or (3) no contradiction.
Explanation-Based Discrepancy Detection
Identify discrepancy spans, generate natural language explanations, and cite violated legal references (for legal contradictions).
Key Results
We evaluated four leading LLMs: GPT-4o-mini, Gemini 2.0 Flash, Gemini 2.5 Flash, and LLaMA 3.3 70B Instruct.
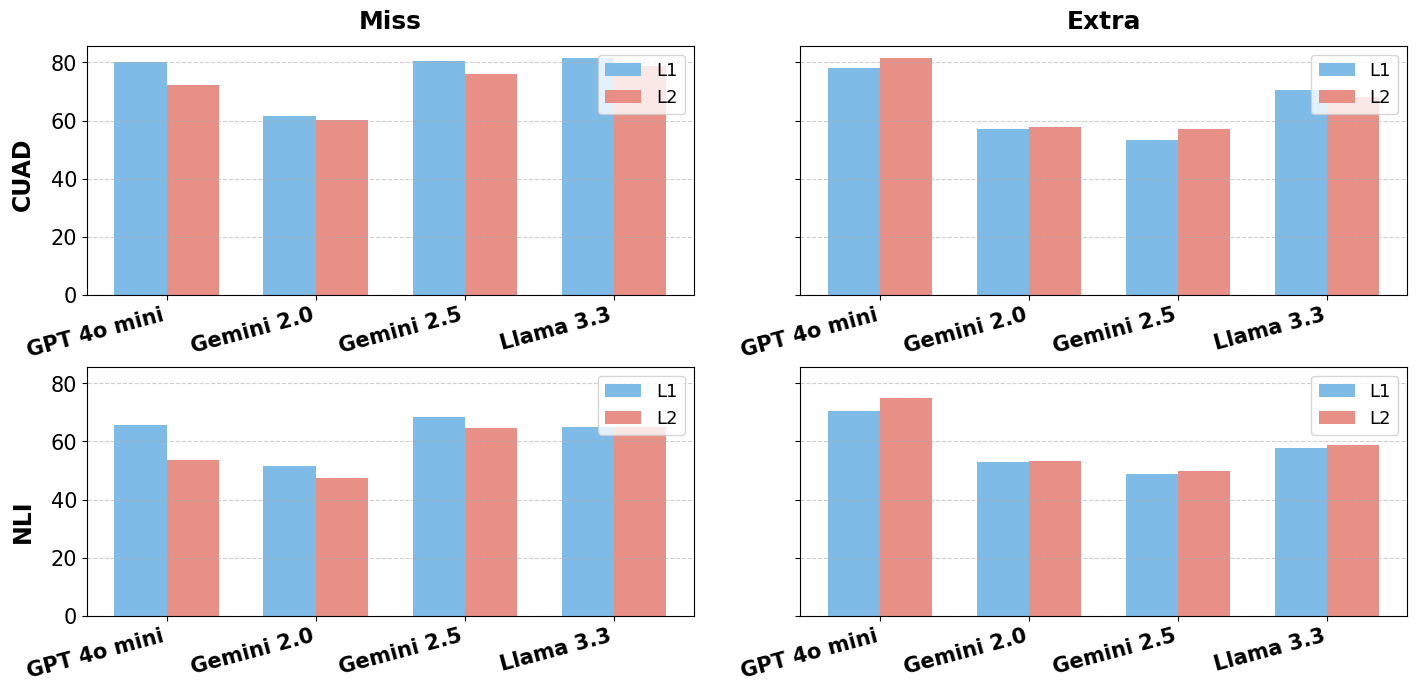
Figure 2: Comparison of model performance showing Miss and Extra rates for CUAD and NLI datasets across L1 (zero-shot) and L2 (one-shot) evaluation levels.
Key Findings
-
Performance Hierarchy: Gemini-2.5 leads with highest F1-scores (63%+ on CUAD), driven by a high-recall (90%+), low-precision strategy. All models perform significantly better on CUAD than the more complex NLI dataset.
-
Category Challenges: Omission_Legal proves exceptionally challenging, with GPT-4o-mini achieving only 31% F1 and LLaMA-3.3 dropping to 9.3% F1 on NLI. Legal discrepancies are consistently harder than in-text contradictions.
-
Explanation Quality Gap: Models generate fluent explanations (Clarity 4.0+) but with low Completeness (<2.0), indicating surface-level coherence without substantive legal depth.
-
Law Citation Weakness: Even the best model (Gemini 2.5) achieves below 14% accuracy in semantically matching legal citations, revealing fundamental gaps in external legal knowledge retrieval.
Eval 1: Binary Detection Results
| Dataset | Category | GPT-4o-mini F1 | Gemini-2.0 F1 | Gemini-2.5 F1 | LLaMA-3.3 F1 |
|---|---|---|---|---|---|
| CUAD | AmbiguityLegal | 41.2 | 60.8 | 63.7 | 53.5 |
| InconsistencyLegal | 42.5 | 60.5 | 63.8 | 53.9 | |
| MisTermLegal | 45.4 | 63.5 | 63.2 | 53.9 | |
| OmissionLegal | 41.8 | 59.7 | 63.8 | 52.2 | |
| StrFlawLegal | 37.9 | 50.9 | 64.2 | 6.9 | |
| NLI | AmbiguityLegal | 38.7 | 46.6 | 47.9 | 14.1 |
| OmissionLegal | 31.6 | 37.6 | 41.3 | 9.3 | |
| StrFlawLegal | 46.5 | 54.6 | 50.4 | 19.8 |
Data Examples
In-Text Contradiction Example
{
"file_name": "DovaPharmaceuticalsInc_10-Q_Promotion_Agreement.txt",
"perturbation": [{
"type": "Omissions - In Text Contradiction",
"original_text": "'Detail(s)' shall mean a Product presentation during a face-to-face sales call... Neither e-details, nor presentations made at conventions...",
"changed_text": "'Detail(s)' shall mean a Product presentation... Presentations made at conventions, exhibit booths, shall constitute a Detail.",
"explanation": "The term 'Detail' is redefined to include presentations at conventions, directly contradicting the original definition that explicitly excluded them.",
"location": "Section 1.19",
"contradicted_location": "Section 4.2.2",
"contradiction_exists": "YES"
}]
}
Legal Contradiction Example
{
"file_name": "PharmagenInc_Endorsement_Agreement.txt",
"perturbation": [{
"type": "Ambiguities - Ambiguous Legal Obligation",
"original_text": "All HDS' uses of Celebrity Attributes... shall be subject to the prior written approval of Celebrity via his agent...",
"changed_text": "All HDS' uses of Celebrity Attributes... should aim to obtain the prior approval... A reasonable effort should be made...",
"contradicted_law": "Lanham Act - False Endorsement",
"law_citation": "15 U.S. Code § 1125(a)",
"law_url1": ["https://www.law.cornell.edu/uscode/text/15/1125"],
"law_explanation": "The modified text creates ambiguity around the approval process, potentially leading to usage without explicit consent, violating the Lanham Act."
}]
}
Citation
If you find this work useful, please cite our paper:
@inproceedings{roychoudhury2025clause,
title={Better Call CLAUSE: A Discrepancy Benchmark for Auditing LLMs Legal Reasoning Capabilities},
author={Roy Choudhury, Manan and Chandramouli, Adithya and Anand, Mannan and Gupta, Vivek},
booktitle={Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (EACL)},
year={2026}
}
Acknowledgements
We are grateful to Rui Heng Foo for his invaluable assistance with the data generation pipelines. We extend our sincere thanks to Arizona State University's Lincoln Center for Applied Ethics, along with their law professors and partners, for lending their expertise to advise on our perturbation categories and to authenticate our perturbed contracts for real-world relevance. We also thank the ASU Law and Pre-Law students for volunteering their time and expertise. Finally, we acknowledge the CoRAL Lab at Arizona State University for providing the computational resources that made this research possible.